
Delete a Search Engine Result Listing from Google
Christian Bullock • February 12, 2018 • 3 minutes to readUh oh. You accidentally pushed a page live.
And it’s showing up in Google searches!
You’re probably asking out loud:
How can I quickly delete this listing from the search engine results page?!
Well, good news! Below are three ways you can ensure a page gets wiped out from Google, Bing, or Yahoo search engine results.
Note: you can only do this for owned web properties. That is, domains that you own. Do note that to be extra sure a URL doesn’t show in search results, we recommend doing a combination of these techniques, even three if you want to send the clearest signal to search engines.
1. Google Search Console / Bing Webmaster Tools
Hopefully you’ve already verified your website for both of these platforms. Verification is easy and you can heaps of terrific insights into the performance of your site.
Google Webmaster Tools allows you to “temporarily” block URLs. This should be used as a band-aid approach to quickly block a URL. You will need to then utilize the second or third way below to completely remove it from Google’s index.
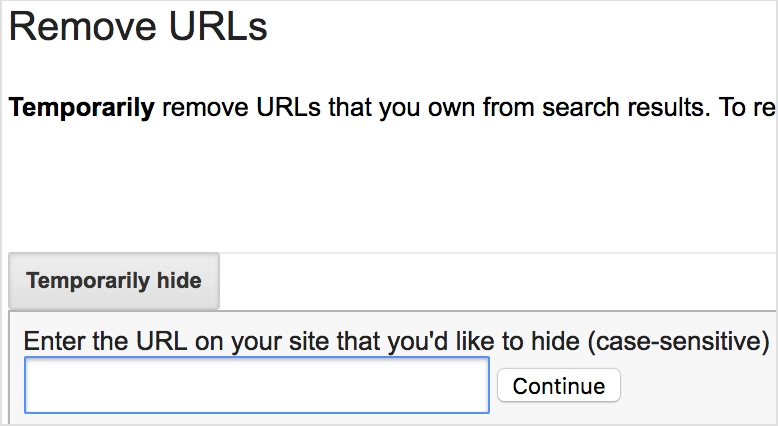
Bing Webmaster Tools is a little more sophisticated with this way of removal. With BWT, you can remove a URL (not just temporarily) and also look to block off a subfolder.

Consider this way your frontline option before moving onto another.
2. Robots.txt
A robots.txt file is the one place search engine spiders go to look for pages or subfolders that they should not crawl.
This file and its specific format is one that all search engines understand.
The file format goes like this:
User-agent: * Disallow: /URL-of-content-you-want-to-block/
You can add just a ‘/’ to disallow all crawling and indexation of your website. You can also input a subfolder to block off a subfolder or a specific URL, as the example above shows. Know that you start immediately after the domain in the structure, as search engine spiders can understand the domain that they’re on when looking at your robots.txt file.
3. Robots meta tag
A robots meta tag is a tag that tells search engines to either index or noindex the page or follow or nofollow links on the page.
This tag is placed in the <head> part of a web page’s code.
An example of robots.txt code that you would want placed for a web page that you don’t want indexed looks like this:
<META NAME="ROBOTS" CONTENT="NOINDEX, NOFOLLOW">
Having this in your page code tells search engine spiders do not index this page and do not follow any of these links.
Stories to share or questions?
Do you have any horror stories of pages you didn’t want to show up in search results? Please share via Twitter! Also let us know if you have any questions about specific issues you may be having with URLs being included in a search engine index.




